- Noah Jacobs Blog
- Posts
- On LLMs - A Crash Course
On LLMs - A Crash Course
What the hell is an LLM and why do people think it will bring about AGI (also what the hell is AGI)
Noah Jacobs
April 26, 2026
2026.04.26
CXLIX
[The Tech We Can’t Shut Up About; A Practitioner’s Take; Transformers, Text Predictors in Disguise; Enter the Chatbot; What’s the Difference?; An LLM’s Memory; A Human’s Memory; Man vs Machine; And AGI]
Thesis: LLMs are still just text prediction engines & have fundamental, critical shortcomings around memory and learning that will prevent them from creating AGI.
[The Tech We Can’t Shut Up About]
It's come to my attention that I've fallen into the trap, particularly last week, of making one of my reader's 'head spin'. I think he thought the comment was something of a compliment, but it was actually an insult. I'm writing about complex things, but my I want to make sure that what I share is clear and understood.
So, this week, I'm going to unpack some of the limitations of LLMs I was circling last week, particularly around what I mean when I said they’re ‘stateless,’ and why this is a problem.
With everybody talking so much about "AI" and "Agents", it’s easy to forget that among the most vocal, there is a super varied understanding of the underlying technology powering them, LLMs (Large Language Models). The two major buckets are:
Have no idea what an LLM fundamentally is (most journalists, most executives, many ai boosters)
Have a functional understanding of what an LLM is but have no incentive to tell you / remind you (maybe Dario/Altman, AI Lab employees or engineers)
I’ve found myself in a third bucket: I have a functional understanding of LLMs and have just kind of been assuming everyone does, too.
Well, today we’re going to fix that. We’re going to talk concretely & simply about what an LLM is. And then, I’ll explain clearly where I believe their limitations lie.
I think this is very important to help understand the technology that everyone won’t stop talking about, so you can have an easier time understanding when someone is spewing bullshit about sentient machines vs when what they say could be important.
[A Practitioner’s Take]
Before we begin, I think it’s important to be very clear about what I am so you can decide how you want to perceive my writing.
I'd never claim to be an AI Researcher, nor am I a neuro-scientist. What I am in someone who:
Spent nearly the last 2 years founding a software company with no outside funding that pays the bills and, importantly, leverages LLMs for core pieces of the functionality in the product I built
has been building products that use LLMs as a key part of their functionality since 2023
Has been writing (with no AI assistance) this weekly blog that often covers AI & Epistemology for the last 2, nearly 3, years.
Has been professionally modeling the world in concrete, quantitative way when I was 18 (~2019) when I started a finance journey that culminated in launching a hedge fund at 21
Focused in finance for undergrad at University of Michigan’s business school, and minored in math for fun at U-Mich more broadly
Has been indirectly studying epistemology since I started reading philosophical texts around the age of 13 or 14 (~2014/15)
Created a poetry book that was one of a kind based on user preferences at 20 (~2021); it used a startling simple AI implementation
I read a decent amount, too
In short, I am a practitioner who has been staring at LLMs for the last 3 years, and has been thinking about modeling the world and decision making and learning for as long as I can remember.
I am not a researcher or an academic, nor would I be interested in posturing as one.
Fundamentally, everyone who is yelling about Claude & GPT & Gemini is betting the house on a text prediction engine. This, to me, seems like a very limited view of what AI can, is, and should be.
Right now, whenever you hear someone say AI, they are almost certainly talking about a Large Language Model (LLM).
An LLM is a giant neural network with transformer architecture.
Generally, you can think about a neural network as a sort of black box that takes in an input on one end and outputs something else on the other end. In the box, there are a series of “hidden layers,” which you can think about as a bunch of functions that take the input of the last function’s output.
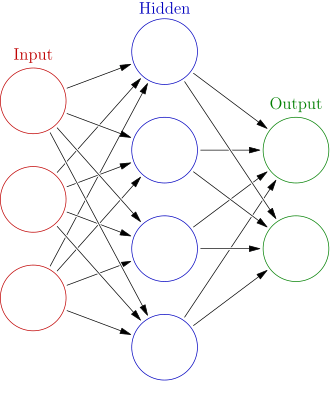
Visualization of a neural network, but there are a lot of different ‘hidden layers’; GPT 3 had 96!
LLMs take in text, but before they pass them into the neural network, they turn the text into “Embeddings.” Embeddings are numerical representations of text. More specifically, they’re vectors with high dimensionality, often thousands of dimensions.
The LLM is trained so that given the text that is converted to embeddings, it can predict the next most likely text in the sequence based on all of the words in the sentence.
Basically, you have a massive amount of text (45TB filtered down to ~570GB for GPT 3) that you turn into these embeddings. Then, you hide parts of that text and ask the model to fill in the blank.
An example for an LLM trained on 90s / early 2000s rap lyrics would be something like:
Input: I never sleep, ‘cause sleep is the cousin of ______
The LLM will have to guesses what the next word is. The first guess could be really bad, like "some guy named Mike," or "grass".
But, since you know what text goes into the blank, you can 'reward' the model for the answer that is closer to the answer that you know is correct.
If it guesses "darkness", you might tell it this was closer to be correct than when it guessed "Sun". And then, eventually, it gets to the correct word, which is “death,” in this case. As you reward it for getting closer, that’s what is creating the ‘hidden layers’ that we talked about above.
So, you might say the ‘machine’ is ‘learning’ the equations that will give it the right output!
This is training, and this is one of the very expensive things that everyone wants to spend money on graphics card to do.
After you're done training it, congrats, you have a model! It's a bunch of equations stacked together that take in text converted to numbers and output the most likely next number that we convert back to text. You can use it in "inference" to take in a previously unseen piece of text, and, hopefully, it predicts the right next word!
If you input: “Yeah, we doin’ big pimpin’ we spendin’______”, if you trained the model right, it should output “cheese.”
This is an LLM, and it’s fundamentally what the AI everyone is talking about run on. It takes in a stream of text and, based on that input, predict the next piece of text.
After we do this, though, it’d be pretty foolish to say that the model is, in fact, Jay Z because we trained it to predict his lyrics! Just like it’d be foolish to train a model on text that includes conversations where things are asked if they’re alive respond in the affirmative, and then say that the model is alive when it responds in the affirmative!
[Enter the Chat Bots]
If you're a bit confused about how we get from a text prediction engine to a chatbot, you should be confused--getting there was actually admittedly a quite clever 'trick', if you will.
A chatbot is still the transformer we talked about above: an LLM that is predicting the next chunk of text.
The trick, though, is that the LLM is being fed in a conversation and asked to predict the next part of the conversation. So, when you're having a conversation with GPT, the real input into the model might look like this:
You are a helpful ai assistant that answers user's questions.
User: Who put the hit out that got pac killed?
Chatbot: ______________Then, the LLM is predicting the next part of the conversation! Of course, there is a lot of fine tuning that goes into it. This means that if you want the LLM to have coherent conversations, you might want to give it a bunch of specific examples that show it what a chatbot ‘should’ respond like.
But, at the end of the day, it’s still just predicting text!
Now that we have a basic understanding of LLMs, I think it is a lot easier to see some very specific, fundamental limitations of the technology that I believe will prevent us from fully copying human intelligence in a meaningful way:
Learning & Memory: Our ability to memorize information and learn on the fly is something that sets us apart from the way LLMs ‘learn’ and ‘memorize’ entirely.
Reasoning: I don't believe that the 'reasoning' LLMs do is at all an analog for how we reason; rather, it's an expensive, if sometimes useful, illusion.
Embodiment & Multi Modal Inputs: This is my weakest and least fleshed out point, but there seems to be something very important about our learning tied to multi sensory inputs and actually existing in physical spaces that I am not convinced can be approximated by embedding video / audio, but I need to do much more research here to have a succinct argument.
Today, we’re only going to primarily focus on Learning & Memory, which on it’s own underline shortcomings that I think are sufficient to throw a damp blanket on any talk of LLMs approximating humans.
In regards to number 2 & 3, those will perhaps be other blog posts on their own.
[An LLM's Memory]
An LLM is fundamentally a stateless machine. This means that, in isolation, if you put an input into an LLM, nothing about the LLM changes after it gives you the output. If you call it again later, you will be calling the same exact system.*
A 'state' is some variable or set of information that you can 'hold on to' or pass around in between calls. The contact app on your phone has a state. If you add a person's information, that person will be there in the future.**
The chatbot or agents built on top of LLMs are stateful. But, importantly, this does not make the underlying LLM stateful.
As you have a conversation with a chatbot, it is taking some of the things you are saying and ‘storing’ them as 'memories'. An unromantic view of this is that it is taking your conversation and compressing it into what it estimates will be important context later. These are not stored ‘in’ the LLM, they’re stored somewhere else. Then, when you have another conversation with the chatbot, those 'memories' are passed into the LLM, along with the text of the conversation.
If this text was not injected into the conversation, the chatbot would not 'know' anything about you. The LLM is not the thing with memories; the application built around it is, and those memories are injected into the LLM when you ask it a question.
And, if we're to speak of agents, nothing here changes, other than the fact that it is now a system that maybe has a more sophisticated way to store and retrieve information. Although you could give a chatbot a more sophisticated way to store information, too. The 'agent' also maybe has access to other tools so it can read and navigate your code base or file system and more easily access more information.
Fundamentally, the LLM itself is not being updated.
*Technical Note: Someone once told me the KV Cache was a 'state.' I think this is massively misleading; it is a state stored during a call, but is not a state stored from call to call. A human with such a limitation would be an amnesiac that couldn’t recall anything earlier than a few seconds ago.
**The contacts in your phone are an example of a very visible state; sometimes, state can be more of a hidden 'side effect', and can be a source of a lot of bugs when you are propgramming!
[A Human's Memory]
How human's learn and memorize things is in sharp contrast to how an LLM learns and memorizes things.
Most useful theories of the brain and memory claim that as we are living experiences, outr brain is being updated in real time. (See Hebbian Theory and Spike-Timing-Dependent-Plasticity as examples).
Meaning, if you burn your hand on a flame, the actual decision making machine is being updated immediately to prevent you from doing that again. Unlike an LLM, it does not require some distinct, separate database or system to be written to.
This is super, super important. A traumatic experience, as an example, can be so impactful on our brain that we literally have a negative emotional reaction that drives us away from the place where it happened or even something we were smelling.
This is contrasted sharply by LLMs.
If it does something stupid, the most practical thing we can hope to do to make it not do that stupid thing again is to store some text that in the most contrived and convoluted way possible amounts to "Don't do that again!" or whatever the day's fanciest 'prompting trick' is. Then, we feed this back into the LLM the next time we call it and hope for the best.
If you're a programmer, this should remind you of the infamous 'bug loops' that LLMs can get into - they make mistake A, and then when they fix mistake A, they introduce mistake B. You ask it to fix Mistake B, and it once again makes Mistake A, even though you just had it solve mistake A moments ago!
This is SUCH a far cry from how human memory works it’s almost laughable to compare a prompt to human memory.
We can also fine tune the LLM to avoid the same mistakes, but this is an expensive and distinct process from actually using the LLM in inference. Imagine if every time you wanted to moderately change your behavior, you had to spend 100s or 1000s times more energy and attention doing so than simply getting burnt once. That’s basically what has to happen to update an LLM.
In short, I’m really hard pressed to believe that prompting can EVER fix memory or learning issues with LLMs. No matter how much you yell at a program designed to predict the next bit of text, you can't guarantee it will actually do what you want!
And as for fine tuning in a effective way, that’s all cutting edge research, not a sure bet.
[Man vs Machine]
To be very clear about the memory issue, I’ll leave you with an anecdote from experience.
When I'm doing jiu jitsu, I've trained myself to have useful reactions to my opponents movements. A lot of these become subconcious responses.
Sometimes, when you are actively trying to get better, you might articulate what you need to do in your native language. If you want to stretch, I guess you could say this is like ‘prompting’ yourself (note how generous I’m being towards people who compare us to LLMs).
I've written about the ompoplata in jiu jitsu quite a bit now. I'm so fascinated by it, because it's a really fucking weird way to break someone's shoulder. Basically, you have to get your opponent face down and chicken wing their arm in between your legs while you're perpendicular to their back. See photo:

The first class I ever went to actually showed this submission, and I was so hopelessly lost during it that I thought it would be impossible to learn.
Now, when I do an omoplate, I do it without thinking about it. I'm not saying 'omoplata time!’ in my head; I’m just doing it.
To learn it, there were intentional moments of 'prompting,' if you will, where I would tell myself real time, "okay, you need to control their posture in guard, get out to your own hip make like you're going for a gogoplata if they move toward you, grab their far hip and put your weight into it as you start to break them down, flip your legs, and maybe use your free hand to mess with their trapped hand if they're doing some funny business."
All of this was once ‘actively’ going on in my brain. Now, if I go to do this motion, unless I am actively trying to improve something about my form, there is none of this. The 'prompt', the information, has updated my brain and just comes out when it is supposed to. It’s ‘natural.’
This is the same with so many other things I, and you, have learned. Using an iPhone, a computer, holding a cup, weightlifting, it goes on and on.
These things are not ‘natural’, they were learned by doing. And once you learn them, they’re there. You don’t need to keep ‘re prompting’ yourself like you do with an LLM.
If you enjoyed this practitioner’s take on AI, shoot me a subscription; I’m around every weekend.
[And AGI…]
To be abundantly clear, I don't think some notion of human like (or superior) intelligence is impossible. I just really really don't think that the current approaches everyone is talking about, namely LLMs and the systems we build around them, are the right tool to get us there.
I think the 'developments' as of late are just slightly different ways to do roughly the same thing (lots of prompting). That’s without even getting into why I think ‘reasoning’ in it’s current state is a scam.
And oh my god, I used AGI (Artificial General Intelligence) in the hook to this post without defining it - it looks like I committed the same crime as fucking everyone who writes about or sells AI.
If you haven't heard of AGI, first off, bless your soul and let me come live with you in your cabin that is somehow insulated from this nonsense.
Secondly, it's this vague, ill defined term that get's thrown around to indicate some sort of AI that is as good as humans at all important things or maybe better depending on who you ask but also let's not define important things because that would be too specific. Here's an article I didn’t read about OpenAi’s definition, but you can probably drop in whatever definition you want, and I'm confident my post still stands.
Any who, there's cool research and other ideas like world models picking up steam that could move us further.
But I'm squarely of the view that making LLMs bigger / training them with more data / giving them 'tools' doesn't bring us much further than we've gotten, and it doesn't actually bring us as far as people claim we're about to be on the back of LLMs alone (re: Dario claiming half of entry level white collar work ‘could’ be replaced by LLMs in 5 years).
Building a system to approximate something as nuanced and complex as the human brain takes time. There are no silver bullets; if one exists, it's certainly not a stateless text prediction engine.
Live Deeply,
